[논문정리]Learning Deep Features for Discriminative Localization (CAM)
2020. 2. 13. 17:50ㆍPapers/Visualization
Learning Deep Features for Discriminatvie Localization
Bolei Zhou, Aditya Khosal, Agata Lapedriza, Aude Oliva, Antonio Torralba Computer Science and Artificial Intelligence Laboratory, MIT
Abstract
- 위치에 대한 정보가 없는 GT(Classification에 대한 정보만 있는 Ground-Truth)이더라도 GAP(Global Average Pooling)을 활용하여 위치화(Localizaiton)능력을 가질 수 있다.
- Bounding Box 정보에 대한 교육 없이 ILSVRC 2014에서 객체 위치 파악에 대해 37.1%(Top-5기준) 달성하였다.
- 해당 네트워크가 분류(Classificaion)에 대한 목표를 가지고 학습하더라도 이미지 영역을 위치화할 수 있음을 보여준다!! ( 추가적인 위치에 관련된 학습을 하지 않고 단순히 분류에 대한 학습만 되어있는 모델을 가지고 위치화를 할 수 있다. 하지만 GAP가 있는 모델의 경우에만 해당 기능을 활용할 수 있다. )
Introduction
- Zhou{여기에 주석할 것} 등의 최근 연구에 다양한 층의 CNN의 Convolution 유닛이 객체의 위치에 대한 정보가 제공되지 않았음에도 불구하고 실로 객체 검출기로서 행동한다는 것을 보여주었다.
- Convolutional layer에서 객체를 지역화할 수 있는 이 놀라운 능력이 있음에도 불구하고 이 기능은 FC(Fully connected layer)가 분류에 사용될 때 손실된다.
- NIN(Network in Network) 및 GoogLeNet과 같이 널리 사용되는 CNN이 파라미터의 수를 최소화하기 위해 FC layer의 사용할 피하면서 높은 성능을 보유한다.
- 이를 성취하기 위해, GAP(Global Average Pooling)을 사용하여 구조적 정규화를하고 학습 도중 overfitting(과적합)을 방지한다.
- GAP 레이어의 장점이 단순히 정규화 역할을 하는 것 이상으로 확정되었음을 발견했다.
- 실제로 약간의 조정만으로도 네트워크는 최종 레이어까지 놀라운 위치화(Localization) 능력을 유지할 수 있다.
- 이 조정을 통해 네트워크가 원래 훈련되지 않은 작업까지도 다양한 작업을 위한 단일 전달-패스에서 식별 가능한 이미지 영역을 쉽게 식별할 수 있다.

- 그림 1을 보면 알 수 있듯이 분류 CNN으로 학습된 모델이 성공적으로 위치화를 하는 것을 볼 수 있다.
Related Work
- CAM 등장 전까지에는 end-to-end 구조가 존재하지 않았다. 하지만 CAM의 경우에는 추가적인 모델 수정이 없이 weight값과 feature map을 활용하여 위치화를 시킬 수 있기 때문에 end-to-end이다.
- 유사한 방법으로 GMP(Global Max Pooling)을 활용한 접근법들이 존재했다.
- GAP 대신 GMP를 활용하여 객체의 위치를 찾아내보았다.
- 하지만, 해당 방법에는 제한적인 것이 존재하였으며 이는 물체의 전체를 보는 것이 아니라 경계 부분만 보는 것이였다.
- 그렇기에 GMP보단 GAP의 경우가 물체 전체에 대해서 보다 잘 식별할 수 있다고 생각한다.
- 지금은 Grad Cam과 같은 방법이 존재하였지만 해당 논문을 기준으로는 굉장히 유니크 했다는 것을 강조함.
- 이는 간단하면서도 추가적인 것 없이 정확하면서도 빠른 위치화를 할 수 있다.
Class Activation Mapping (CAM)
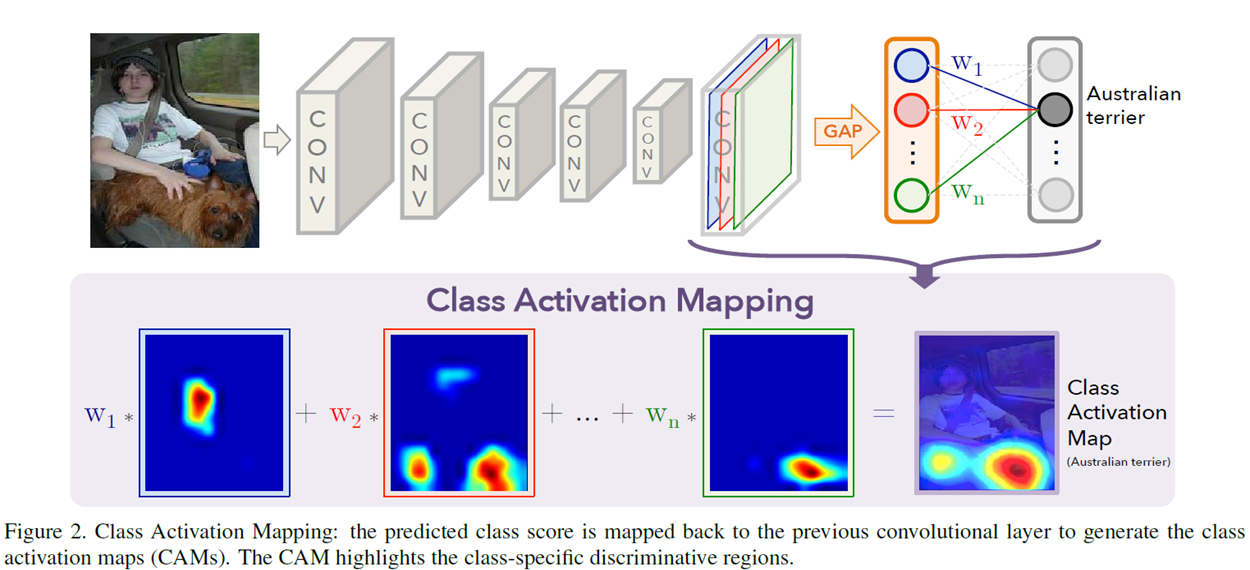


- 위의 그림 2,3,4 를 보면 알 수 있듯이 CAM은 다음과 같이 진행된다.
- 그림 2를 보면 알 수 있듯이 Softmax하기전 layer의 weight를 활용한다.
- ResNet을 예시로 든다면 Softmax를 하기전 최종적인 output은 입력이미지 224X224X3기준으로 7X7X512이다. 해당 값은 GAP이후의 값은 1X1X512크기로 변환되며 이는 fully connect가 되기 위해 input의 크기는 512XClasses(하나의 클래스에 대해서 작업하기 때문에 classes값은 1이다.)이다. 해당 값을 GAP가 되기전 Convolutional layer의 Feature map과 행렬곱을 하여 사용한다. 해당 연산이 된 값을 이미지에 Heatmap 적용을 하여 표현한다. 그러한 결과가 그림 3과 4의 결과이다. 하나의 이미지에 대해서도 다른 class에 대한 위치화를 한다면 다른 결과가 나타난다.
- 결과론적으로 위치화의 최종목표는 찾은 정답 분류에 대한 위치화이기 때문에 softmax를 통해 추출된 값중 가장 높은 값에 대한 CAM을 적용하는 것이다.
- $f_k(x,y)$는 마지막 convoltuional layer의 위치 $(x,y)$에서의 유닛 k의 활성화를 의미한다.
- 그 후, unit $k$에 대해서, GAP의 결과 $F^k$는 $\sum_{x,y}f_k(x,y)$라 표현할 수 있다.
- 클래스 $c$가 주어졌을때, softmax의 입력은, $S_c$는 $\sum_kw^{c}_kF_k$라 할 수 있으며, $w_k^c$는 유닛 $k$에서 클래스 $c$와 일치하는 weight값이다.
- 마지막으로 출력은 softmax를 통한 $P_c = \frac{exp(S_c)}{\sum_{c}exp(S_c)}$
$S_c = \sum_kw_k^c\sum_{x,y}f_k(x,y)=\sum_{x,y}\sum_kw_k^cf_k(x,y). (1)$
- 위와 같이 표현할 수 있다.
- 해당 값을 CAM을 $M_c$라고 정의한다면, 아래와 같이 표현할 있다.
$ M_c(x,y) = \sum_kw_k^cf_k(x,y). (2)$
- 일반적으로 class를 정답이라고 예측된 값에 대하여라고 생각하지만 이를 수정하여 정답이라고 예측한 것 외의 class에 대해서도 위치화를 할 수 있다.
- 자세한 내용은 pytorch로 구현된 소스를 보여주면서 설명할 예정이다.
Global Average Pooling vs Global Max Pooling
- GMP와 GAP를 사용하였을때 중요하다고 생각하는 부분의 하이라이트 위치가 다름을 볼 수 있다.
- GAP는 단 하나의 판별적인 부분을 활용하는 GMP(2X2기준이라고 생각한다면 4개의 값중 하나만을 활용하기 때문에 다음과 같이 얘기함)와 비교하여 네트워크가 대상의 범위를 식별하도록 장려한다고 생각함.
- GMP의 경우에는 가장 판별적인 영역을 제외한 모든 이미지 영역에서 낮은 점수는 점수 영향에 미치지 않는다. 따라서 활용되질 않는다.
- 반대로 GAP의 경우에는 점수에 모든 영역의 점수들이 반영되는 점이 존재함.
- 실험을 통해 GMP는 GAP와 유사한 분류 성능을 달성하지만 위치화에 대해서는 GMP는 GAP에 비해 성능이 떨어지는 것을 알 수 있다.
Result

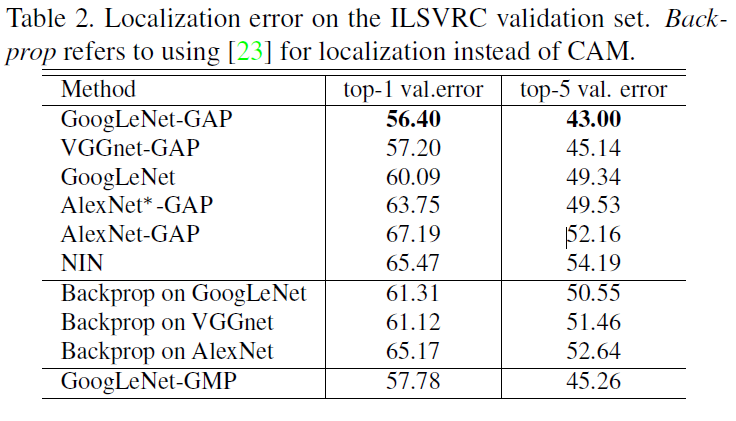


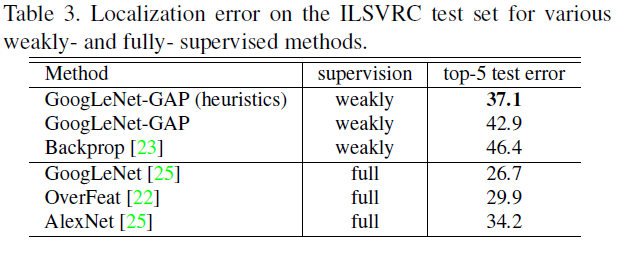

Conclusion
- GAP를 사용한 CNN을 활용하는 Class Activation Mapping(CAM) 기술을 소개했다.
- 이는 어떠한 bounding box 정보 없이 classification에 대해서 모델을 학습하더라도 위치화를 할 수 있다.
- 클래스를 주어주었을 때 해당 클레스에 맞는 위치에 heatmap을 통해 강조할 수 있다.
- 위치화에 대한 학습 없이도 위치화에 대해 학습한 모델들과 나름 유사한 성능을 얻을 수 있다.
Source 부분
작업환경 : pytorch
source github url
직접 학습을 해보면서 확인하기 위해서 학습시간을 단축을 위해 모델 입력 이미지 크기를 128X128로 낮춘 상태로 학습을 진행하여 CIFAR10기준 accuracy가 낮다. 하지만 어느 모델을 활용하더라도 추가적인 학습이 필요로하지 않기 때문에 보다 정확한 CAM 능력을 확인하기 위해서는 ImageNet으로 pretrained된 모델을 사용하여 확인해보면 보다 나은 성능을 얻을 수 있다.
- CIFAR10의 경우에는 이미지 크기가 32X32로 굉장히 작은편에 속하기 때문에 결과를 늘려서 봤을 때 다른 dataset에 비하면 비교하기 안좋은 편이다.
- 사용 방법은 readme를 업데이트하여 도움을 줄 수 있도록 할 예정
$S_c = \sum_kw_k^c\sum_{x,y}f_k(x,y)=\sum_{x,y}\sum_kw_k^cf_k(x,y). (1)$
def returnCAM(feature_conv, weight_softmax, class_idx):
# generate the class activation maps upsample to 256x256
size_upsample = (128, 128)
#size_upsample = (256, 256)
#print(feature_conv.shape)
bz, nc, h, w = feature_conv.shape
output_cam = []
for idx in class_idx:
cam = weight_softmax[class_idx].dot(feature_conv.reshape((nc, h*w))) # [1X512].dot([512,h*w(4X4)]) 하나의 클래스에 대해서
cam = cam.reshape(h, w) # [1X16] -> [4X4]여기서 weight_softmax는 위의 식에서 $w_k^c$를 의미하며, feature_conv는 $f_k(x,y)$를 의미한다.
resnet-CAM.py파일에 feature_conv의 값을 hook을 통해 list로 만드는 과정이 있으며, weight_softmax는 model.parameters를 통해 index접근을 통해 가장 마지막 전 layer의 paramter(Fully connected layer)의 값을 가져오는 작업이 있다.
def hook_feature(module, input, output):
print(output.shape)
features_blobs.append(output.data.cpu().numpy())
resnet18_custom._modules.get(final_layer).register_forward_hook(hook_feature)위의 식을 통하여 마지막 layer의 forward방향에서의 feature map의 값을 가져올 수 있다. backward 값을 가져오기 의해서는 register_backward_hook을 활용하면 된다.
params = list(net.parameters())
weight_softmax = np.squeeze(params[-2].data.cpu().numpy()) # parameter fully connected layer input = 512 output = 10위와 같이 list로 변환 후 softmax weight값을 가져올 수 있다. 여기서 squeeze는 batch에 해당하는 값을 없애기 위함이며 gpu를 활용하여 학습 및 테스트를 하도록 설정하였기에 데이터 형태를 cpu형태로 바꾼 후 활용한다.

실제로 위치에 대한 학습 없이 CAM을 활용하여 어느 부분을 보고 해당 클래스라고 판단하였는지 확인할 수 있다.
'Papers > Visualization' 카테고리의 다른 글
| [논문정리] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (0) | 2020.02.21 |
|---|