[논문정리] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (SRGAN)
2019. 12. 19. 20:27ㆍPapers/Super Resolution
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4681-4690
Abstract
- 기존에 존재하는 깊고 빠른 CNN을 사용하여 단일 이미지 super-resolution의 속도와 정확성 향상에도 불구하고 여전히 해결되지 않은 큰 문제가 있다.
- 큰 Upscaling 요소에서 super-resolve을 할 때 더 미세한 텍스처 디테일을 어떻게 복구할 것인가에 대해서 이다.
- 최근 연구는 평균 제곱 재구성 오류(mean squared reconstruction error)를 최소화하는데 주로 초점을 맞췄다.
- 결과 추정 값들은 피크 신호 대 잡음비(PSNR)가 높지만 종종 고주파 세부 정보(high-frequency detail)가 부족하고 더 높은 해상도에서 기대되는 충실도와 일치하지 않다는 관점에서 만족스럽지 못한다.
- 해당 방법들(PSNR,MSE)로 측정한 것들이 수치상일 뿐 정확한 측정법이 아니다.
- 해당 논문에서는 이미지를 고해상도로 만들기 위한 GAN인 SRGAN(Super-resolution generative adversarial network) 을 소개한다.
- 우리가 아는 한, SRGAN은 4배 확대 요소에 대해서 사실적이게 자연스러운 이미지 추론할 수 있는 최초의 프레임워크이다. (2017년도 기)
- 이를 위해 adversarial loss와 content loss로 구성된 perceptual loss function 을 제안한다.
- Adversarial loss는 초 해상도 이미지와 원본 이미지를 구별하도록 훈련 된 판별기(discriminator) 네트워크를 사용하여 솔루션을 자연 스러운 이미지로 만들수 있도록 한다.
- 또한 픽셀 공간의 유사성 대신 perceptual 유사성에 의해 유발 된 content loss를 사용합니다.
- SRGAN으로 얻은 MOS(mean-opinion-score) 점수는 최첨단 방법으로 얻은 것보다 원본 고해상도 이미지의 점수에 더 가깝게 나타났다.
Introduction
- 저해상도(LR)에서 고해상도(HR)이미지를 추정하는 매우 어려운 작업을 SR(Super-resolution)이라고 한다.
- SR은 컴퓨터 비전 연구 커뮤니티에서 상당한 관심을 받았으며 광범위한 응용 프로그램을 보유하고 있다.
- Supervised SR알고리즘의 최적화 목표는 일반적으로 복구 된 HR이미지와 정답 사이의 MSE(mean squared error) 를 최소화하는 것입니다.
- 이는 MSE를 최소화하면 SR 알고리즘을 평가하고 비교하는 데 사용되는 일반적인 측정치인 PSNR(peak signal-to-noise ratio) 를 최대화하기 때문에 편리합니다.
- 그러나 높은 텍스처 디테일과 같이 지각적으로 관련된 차이를 캡처하는 MSE의 기능은 픽셀 단위 이미지 차이를 기반으로 정의되므로 매우 제한적이다.
- 이는 아래 그림에 나와 있으며, 가장 높은 PSNR이 지각적으로 더 나은 SR 결과를 반영 할 필요는 없다.

- PSNR이 높을수록 원본 이미지와 차이가 적다는 것을 의미하는데 위의 그림을 보면 PSNR이 가장 낮은 SRGAN이 육안으로 봤을 때 가장 원본 이미지와 유사함을 느낄 수 있다.
- 그렇기에 논문에서 PSNR과 MSE가 디테일에 관련된 부분을 생각하면 절대적인 측정 방법이 아님을 언급한다.
- 이 작업에서 우리는 skip-connection 이 있는 깊은 residual network(ResNet) 을 사용하고 MSE에서 유일한 최적화 대상으로 분기하는 super-resolution GAN(SRGAN) 을 제안한다.
- 이전 연구와 달리, 우리는 HR 참조 이미지와 지각적으로 어려운 솔루션을 장려하는 판별기와 결합 된 VGG network의 high-level feature maps을 사용하여 새로운 loss functiond을 정의합니다.
- 기존의 경우에는 generator을 통해 만들어진 SR이미지와 HR이미지를 다른 전처리 없이 MSE를 통해 loss를 구했는데 이 방식은 shift와 같은 상황에 대해서 취약한 부분이 존재했기에 이를 해결하기 위해서 VGG network를 평가모델로 사용하여 추출된 feature map을 사용하여 loss를 계산하는 방식을 활용함
Related works
Image super-resolution
- 기존에 SR을 하기 위한 방버들은 많이 있었다.
- 최근에 CNN기반의 SR 알고리즘이 굉장히 높은 성능을 보였다.
- Bicubic 보간(interpolation)을 사용하여 입력 이미지를 up scale하고 3개의 deep fully convolutional network를 end-to-end로 만들어서 학습시켜 높은 성능을 얻었다.
- 속도와 정확도를 높이기 위해 추가적인 방법들이 제안되었다.
Design CNN
-
컴퓨터 비전 문제 대다수는 CNN으로 해결하고 있다.
-
Deeper network architectures은 학습하기 어렵지만 매우 높은 복잡성의 모델 매핑을 허락하고 네트워크의 정확성을 높여주는 잠재성을 가지고 있다.
-
이러한 deeper network architectures를 효율적으로 훈련시키기 위해 batch-norm 을 사용하여 내부 co-variate shift에 대응한다.
-
또 다른 최근에 소개된 개념은 residual blocks 와 skip-connection 이다.
-
skip-connection은 본질적으로 사소한 identity 매핑 모델링의 네트워크 아키텍처를 완화하지만, 잠재적으로 convolutional kernel로 표현하는 것은 쉽지 않다.
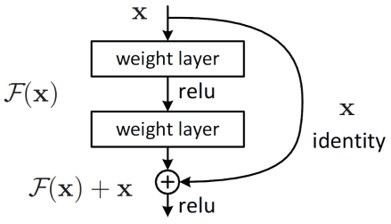
-
SISR(Single Image Super Resolution)의 맥락에서, up scale 필터를 학습하는 것이 정확성 및 속도 측면에서 유리하다는 것이 밝혀졌다.
Loss function
- 결과를 바로 MSE하는 것이 아닌 VGG19와 같은 Network를 통해서 추출된 값을 사용하여 Loss 계산을 하는 것이 효율적이라는 것이 밝혀졌다.
- 이와 같은 내용에 대해서 연구하는게 많아지고 있다.
Method

)

Adversarial network architectures

Generator & Discriminator Network architecture
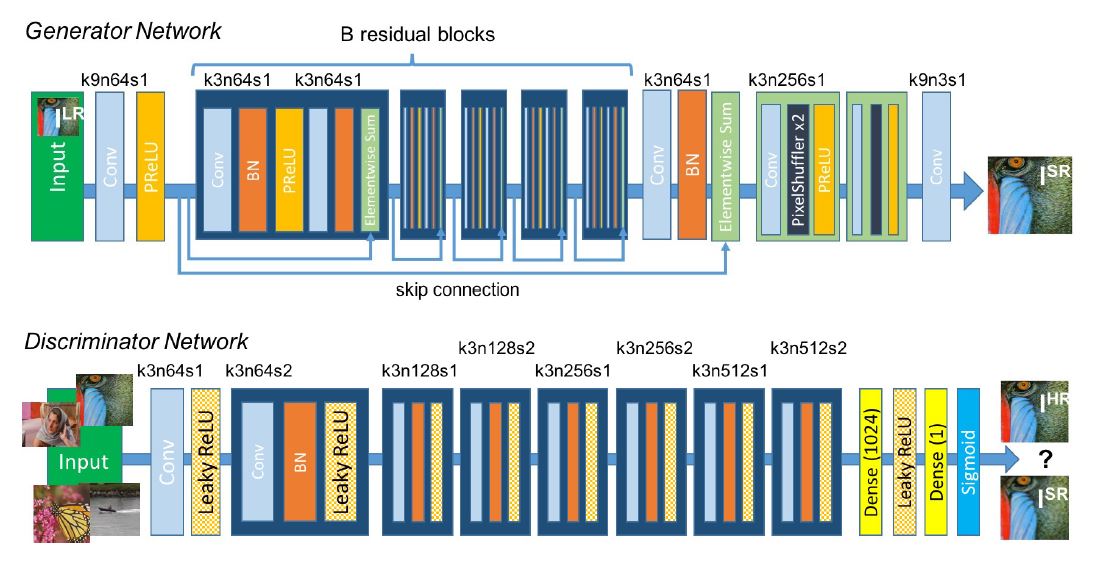
Perceptual loss function

Content loss
Without VGG Network

With VGG Network

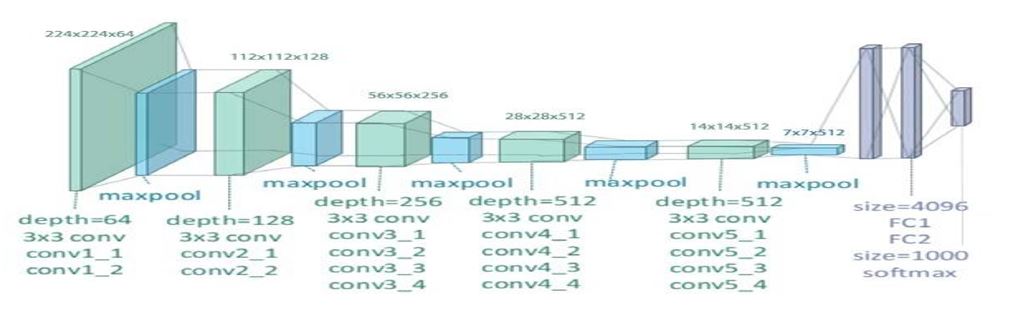
VGG19 network architecture
Adversarial loss
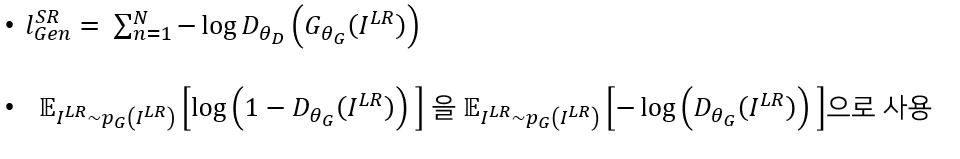
Experiments
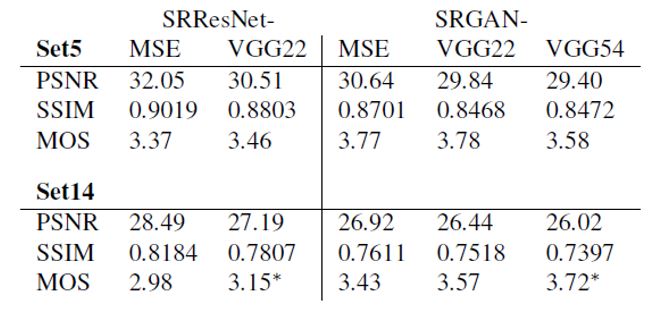
SRRestNet과 SRGAN에서 content loss 사용 방법에 따른 성능 비교
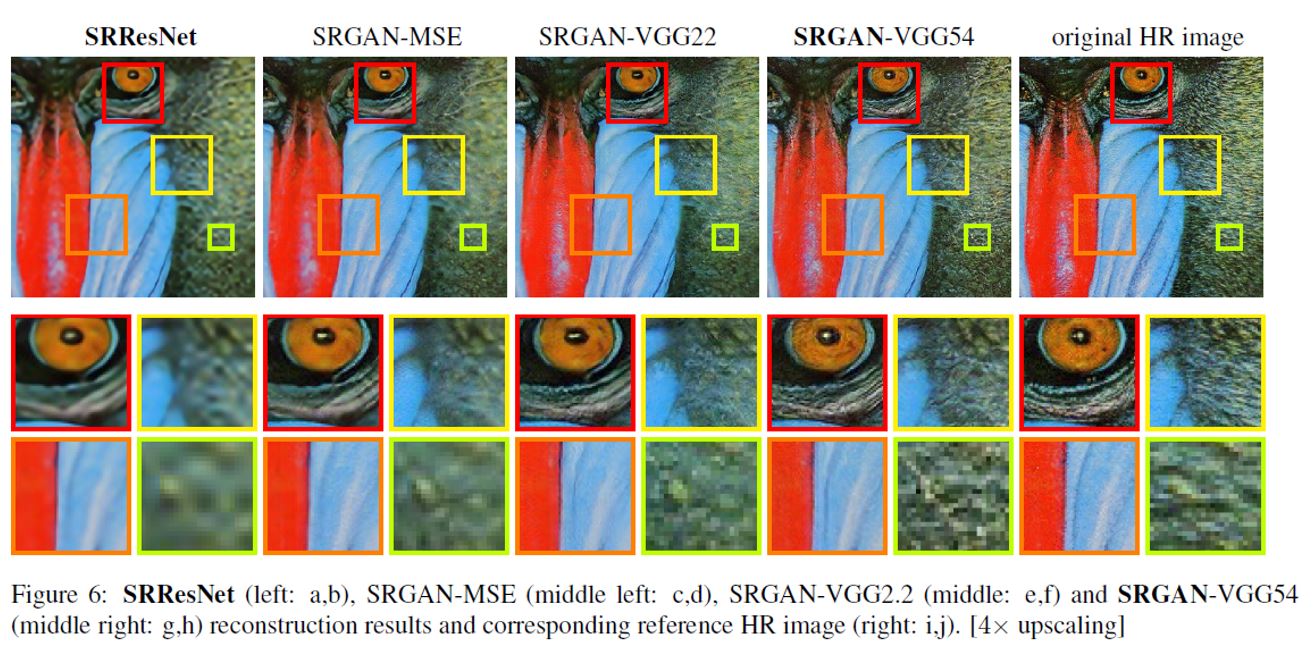
대표적인 비교 데이터셋을 통한 성능 비교
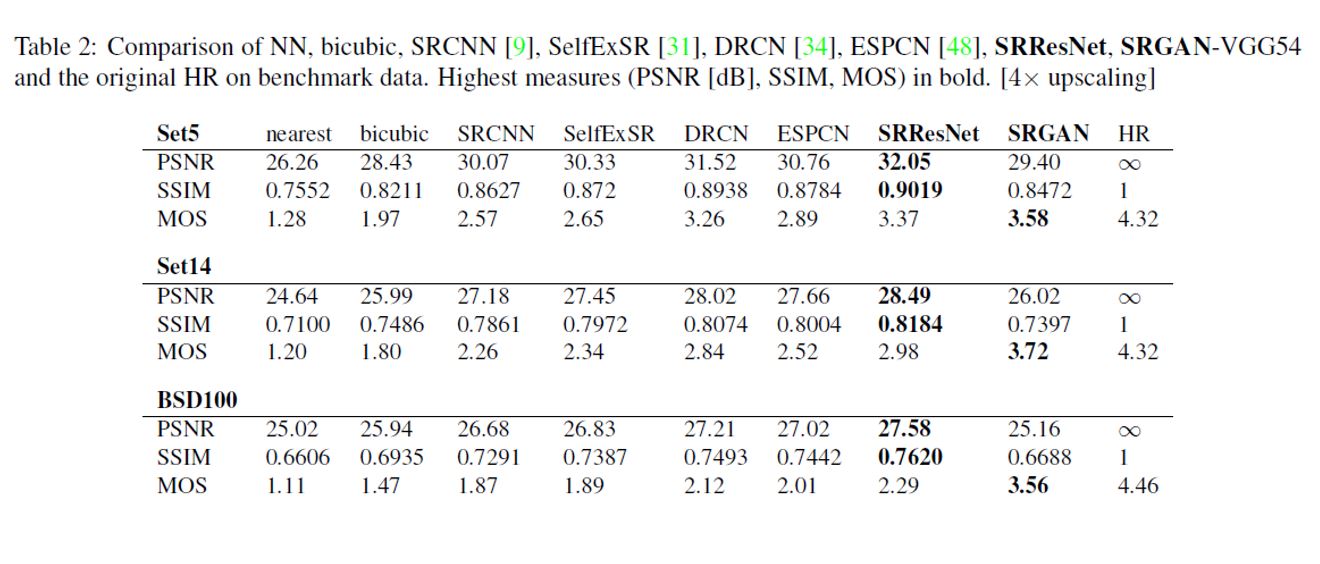
논문에 기재된 비교 이미지

)

)

소스를 통한 분석
기본 이론
Interpolation
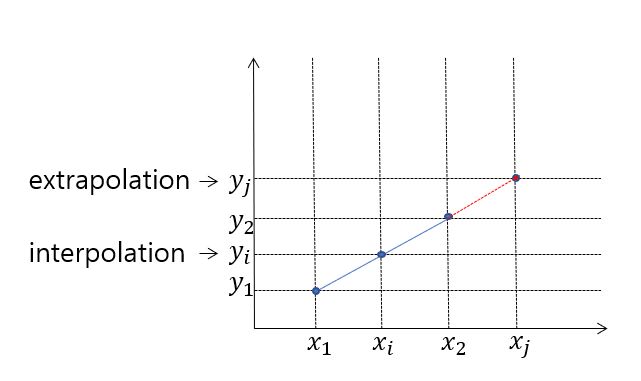
- Interpolation(보간)이란 알려진 지점의 값 사이에 위치한 값을 알려진 값으로부터 추정하는 것
- Interpolation과 대비되는 용어로 extrapolation이 있는데, 이는 알려진 값들 사이의 값이 아닌 범위를 벗어난 외부의 위치에서의 값을 추정하는 것을 말
PSNR & MSE

Pytorch관련 설치법
-
환경설정(설치)
- cuda toolkit 10.1
- cudnn 7.6.5 for cuda toolkit 10.1
- 그래픽 드라이버(NVIDIA)
- Anaconda (가상환경을 사용해서 할 경우) 권장
-
설치 필요 패키지
- python version = 3.7
- conda install pytorch torchvision cudatoolkit-10.1 -c pytorch
- pip install torchsummary(모델 구조를 쉽게 보기 위함)
- pip install opencv-python
- conda install matplotlib
- etc ... ( 그 외 필요 라이브러리를 설치하여 사용하면 됩니다 )
소스분석
데이터 처리 ( 정규화 및 resize )
# Normalization parameters for pre-trained PyTorch models
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
class ImageDataset(Dataset):
def __init__(self, root, hr_shape, max_index): # download, read data 등등을 하는 파트
hr_height, hr_width = hr_shape # 256 X 256
self.max_index = max_index
# Transforms for low resolution images and high resolution images
self.lr_transform = transforms.Compose( # 고해상도로 만들 데이터인 low resolution data
[
transforms.Resize((hr_height // 4, hr_height // 4), Image.BICUBIC), # 기본 width, height에서 4를 나눈 값으로 resize
transforms.ToTensor(), # image값을 tensor형태로 변환
transforms.Normalize(mean, std), # 위에서 선언한 mean, std값을 사용하여 0~1사이로 Normalize
]
)
self.hr_transform = transforms.Compose( # high resolution image 데이터
[
transforms.Resize((hr_height, hr_height), Image.BICUBIC), # BICUBIC : 주변 16개의 픽셀을 사용하여 처리
transforms.ToTensor(),
transforms.Normalize(mean, std),
]
)
self.files = sorted(glob.glob(root + "/*.*")) # 오름차순으로 파일 정렬
def __getitem__(self, index): # 인덱스에 해당하는 아이템을 넘겨주는 파트
if index <= self.max_index:
img = Image.open(self.files[index % len(self.files)])
img_lr = self.lr_transform(img)
img_hr = self.hr_transform(img)
return {"lr": img_lr, "hr": img_hr} # map 형태로 반환
def __len__(self): # data size를 넘겨주는 파트
return self.max_index # 파일 길이 반환 ( 총 이미지 수 )평가로 사용하기 위한 VGG19 model (pre_train model 사용)
class FeatureExtractor(nn.Module): # Feature Extract Model
def __init__(self):
super(FeatureExtractor, self).__init__()
vgg19_model = vgg19(pretrained=True) # pretrained된 vgg19 model
self.feature_extractor = nn.Sequential(*list(vgg19_model.features.children())[:36])
def forward(self, img): # forward
return self.feature_extractor(img)- 해당 VGG19 모델은 GAN을 통해서 생성한 이미지와 기존 HR이미지의 비교를 위해 사용할 모델이기 때문에 weight update는 진행하지 않으며 단순 eval용으로 사용
ResidualBlock
class ResidualBlock(nn.Module): # ResNet BasicBlock
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1), # 3X3 conv filter = same
nn.BatchNorm2d(in_features, 0.8), # batch normalization
nn.PReLU(), # PReLU => y = ax (if a = 0.1 ==> Leaky ReLU) 여기서 a(알파)는 학습을 통해 결정됨
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1), # 3X3 conv filter = same
nn.BatchNorm2d(in_features, 0.8), # batch normalization
)
def forward(self, x):
result = x + self.conv_block(x)
return result # concat ( skip connection )- 논문에서 언급한 ResdualBlock result = x + self.conv_block(x)작업이 skip-connection 작업이다.
###Generator
lass GeneratorResNet(nn.Module): # 생성자 ( Generator )
def __init__(self, in_channels=3, out_channels=3, n_residual_blocks=16): # Low resolution Tensor를 사용하여 High resolution을 생성
super(GeneratorResNet, self).__init__()
# First layer
self.conv1 = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=9, stride=1, padding=4), nn.PReLU())
# Residual blocks
res_blocks = []
for _ in range(n_residual_blocks):
res_blocks.append(ResidualBlock(64))
self.res_blocks = nn.Sequential(*res_blocks)
# Second conv layer post residual blocks
self.conv2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(64, 0.8))
# Upsampling layers
upsampling = []
for out_features in range(2):
upsampling += [
# nn.Upsample(scale_factor=2),
nn.Conv2d(64, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.PixelShuffle(upscale_factor=2), # upscale
nn.PReLU(),
]
self.upsampling = nn.Sequential(*upsampling)
# Final output layer
self.conv3 = nn.Sequential(nn.Conv2d(64, out_channels, kernel_size=9, stride=1, padding=4), nn.Tanh())
def forward(self, x):
out1 = self.conv1(x)
out = self.res_blocks(out1) # total 16개의 Residual_block으로 구성됨
out2 = self.conv2(out)
#print("out1 result : ",out1.shape)
#print("out2 result : ",out2.shape)
out = torch.add(out1, out2) # 덧셈 concat가 아닌 value 덧셈
#print("torch.add result : ",out.shape)
out = self.upsampling(out) # 2번 반복 64 -> 128 // 128-> 256 순으로
out = self.conv3(out) # channel 64 -> 3 (super resolution 마지막 단계)
return out- 16개의 ResidualBlock으로 구성되어 있으며 PixelShuffle을 통해 upsampling을 진행함 (4배수 만큼)
Discriminator
class Discriminator_withDense_paper(nn.Module): # 논문과 일치하도록 Dense를 사용
def __init__(self, input_shape):
super(Discriminator_withDense_paper, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, stride=1, padding=1))
if not first_block:
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, first_block=(i == 0)))
in_filters = out_filters
#layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, padding=1)) # 논문 구조에는 없는 부분이지만 해당 부분 없이 바로
#Dense를 할 경우 Param수가 급등함으로써 학습이 어려워짐.
self.model = nn.Sequential(*layers)
layers2 = []
layers2.append(nn.Linear(16*16*512,1024))
layers2.append(nn.LeakyReLU(0.2, inplace=True))
layers2.append(nn.Linear(1024,1))
layers2.append(nn.Sigmoid())
self.model2 = nn.Sequential(*layers2)
def forward(self, img):
x = self.model(img)
x = x.view(x.size(0),-1)
return self.model2(x)- 논문에서 나온 Discriminator network
- 다음과 같이 진행 시 첫 번째 Dense에서의 params수가 급증함으로써 모델의 크기가 비약적으로 크게 증가한다. 따라서 open source에서는 다른 방법들을 사용하여 이를 처리함
- Conv를 한번 더 한다던가 output크기를 논문과 다르게 한다던가...
실제 훈련을 통한 실행 결과

- test시 epoch가 동일하지 않은 점에서 정확한 비교가 되지 않는다.
- 실질적으로 F1 loss를 content loss로 사용하였을 때 가장 높은 성능을 확인하였다.
- 색감적인 부분에 있어서 SRGAN이 interpolation방법들 보다 많이 떨어지는 모습을 보여주는데 해당 문제는 소스딴에서 문제가 존재하기 때문에 해결하지 못했다고 생각함.
- VGG19에서의 Feature Extract 위치에 따라서 성능 차이를 볼 수 있음.
- 데이터셋 이미지의 양이 약 22만4천장임에도 불구하고 RTX2070사용시 batch size를 8보다 크게 할 수 없기 때문에 학습속도가 굉장히 느림 (전체데이터셋을 1epoch에 다학습한다고 할 시 약 8시간 이상이 걸림)
- 따라서 테스트를 하기 위해서 약 전체 데이터셋에서 일부를 가져와서 학습하는 식으로 진행하였기 때문에 많은 데이터셋을 활용했다고 볼 수 없음
결론
- SRGAN을 통해서 저해상도 이미지를 고해상도로 복구한 경우 기존에 존재한 interpolation들을 사용한 방법보다는 보다 자연스러운 이미지로 복구가 가능함
- 하지만 학습 과정에서의 문제 혹은 논문과는 완벽하게 일치하지 않는 학습 방법으로 학습 또는 같은 데이터셋으로 훈련을 했는지에 대한 부분에 따라서 다른 결과를 보임 ( 색감 쪽에서 좋지 않은 성능을 보임)
- 결과적으로 자연스러운 이미지를 복구 할 수 있음을 육안으로 확인할 수 있었기에 좋은 결과라고 판단
- 추후 다른 SR 관련 GAN을 추가적으로 공부할 예정
소스코드 github
- source을 참조하여 주시면 됩니다.
'Papers > Super Resolution' 카테고리의 다른 글
| [논문정리] Second-order Attention Network for Single Image Super-Resolution (0) | 2020.01.03 |
|---|---|
| [논문정리] Enhanced Deep Residual Networks for Single Image Super-Resolution (0) | 2019.12.24 |