[논문읽기] A Simple Framework for Contrastive Learning of Visual Representations(SimCLR)
2022. 3. 4. 17:23ㆍPapers/Contrastive Learning
A Simple Framework for Contrastive Learning of Visual Representations
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR.
Main idea
- 본 논문 SimCLR에서 기존 unsupervised contrastive learning 방법들과 가장 큰 차이점은 memory bank를 활용하지 않는 점이 존재한다.
- Memory bank method를 활용했을 경우 memory issue문제가 컸던 점이 존재한다.
- 두개의 서로 다른 Data augmentation을 통하여 positive sample을 생성하며, 두개의 sample에 대해서는 pull하도록 학습하고, 그 외의 sample에 대해서는 push를 통하여 모델 표현 학습을 최적화 시킨다.
- feature extract를 통하여 추출한 feature 값을 그대로 metric smiliarity를 계산하는 것이 아닌 normalization을 통하여 값을 변화시켜줌으로써 보다 높은 성능을 얻어냈다.
- 추후, MoCo 업데이트 버전에서 해당 방식을 채용한 것으로 알고 있음.
- 적절한 temperature parameter $\tau$와 위에 언급한 normalized embeddings이 학습에 도움을 준다.
- Memory bank를 활용하지 않기 때문에 충분한 negative sample을 활용하기 위해서 batch size를 크게 설정하여 학습을 수행하는 차별성이 존재한다.
- 다른 후속 논문에서 무조건 적으로 negative sample이 많아야 contrastive learning 학습에 도움이 많이 되는가에 대한 논문도 있었는데, 해당 논문은 추후 다뤄보도록 하겠습니다.
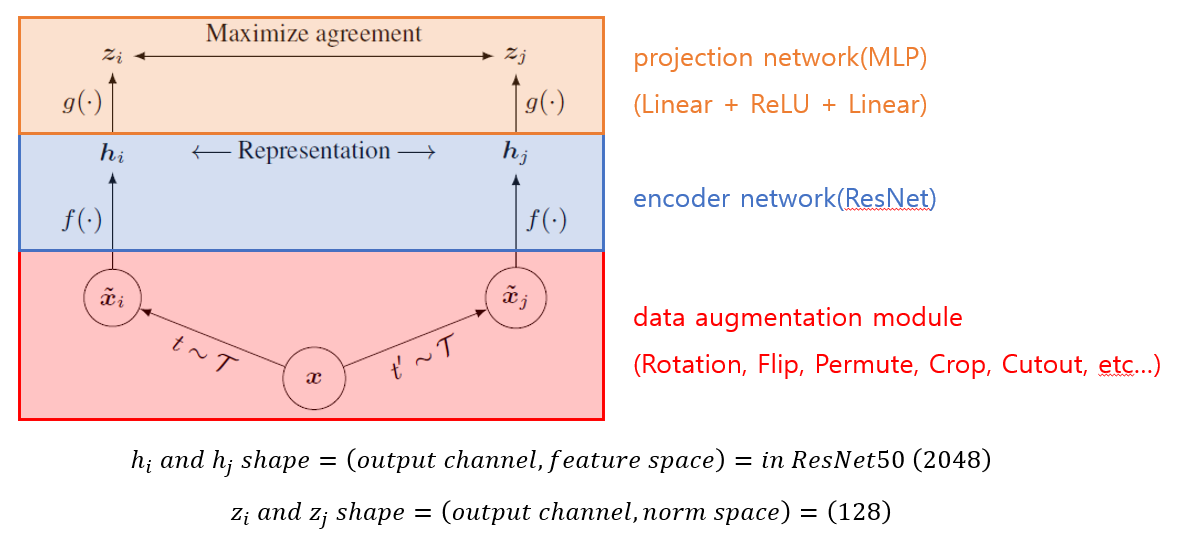
SimCLR의 전체적인 흐름은 위의 그림으로 모두 설명할 수 있다.
SimCLR은 총 3개의 부분으로 구성되어 있는데, Data augmetation module, feature extract module, 그리고 normalization module로 구성되어 있다. 각각의 module이 하는 역할은 다음과 같다.
- Data augmentation module : positive sample과 negative sample을 생성하기 위하여 활용되는 모듈이다. 선택된 anchor image 기반으로 서로 다른 두개의 data augmentation을 적용하여 $\tilde{x_{i}}, \tilde{x_{j}}$를 생성한다. 두개의 sample은 positive sample로서 동작하며, 추후 feature extract module과 normalization module을 통과한 metric에 대해서 pull을 통하여 값을 최대화 하도록 학습시킨다.
- Feature extract module : 해당 모듈은 일반적으로 활용되는 ResNet과 같은 모델의 feature extract부분만 활용하는 모듈로, 마지막의 classifier layer를 제거하여 활용한다. 본 논문에서는 총 2개의 backbone model을 feature exttract module로 활용하는데, ResNet-50과 ResNet-200을 채택하여 실험을 진행하였다. 본 ResNet 모델 두개는 최종적으로 classifier layer에 들어가기 전 Global Average Pooling을 통과한 후의 feature shape은 $(batch, 2048)$과 같다.
- Normalization module : 이전 연구들에서는 해당 모듈을 활용하지 않고 feature extract module을 통해 나온 feature space값을 바로 비교하였다. 실험적으로 본 논문에서는 normalization module을 활용하여 차원을 128까지 압축시키면서 값을 normalization을 수행하는 것이 성능적인 면에서 좋다는 결과를 얻어 다음과 같은 모듈을 활용하였다. 실제로 타 후속 논문들도 normalization module을 많이 채택하였다.
Loss fucntion

- 이전 Memory bank method를 활용하는 것이 아니라 batch 안에서 positive sample과 negative sample을 활용하기 때문에 Batch 단위로 sampling을 수행하게 된다. 여기서 가장 충요한 점은 i의 개수가 2N이라는 것이다. 왜 Batch size가 N인데 i의 크기는 2N인가에 대해서 생각을 꼭 할 필요가 있다.
- 2N인 이유는 Data augmentation을 두가지 방식으로 활용했다는 점에 있다. Anchor sample에 대해서 Positive sample을 생성하기 위하여 서로 다른 Data Augmentation을 적용하게 되는데, 따라서 기존 B의 크기가 512라면 실제 학습에 활용되는 image sample의 수는 2N인 1024가 된다.
- 해당 식에서 가장 중요한 것은 분자와 분모의 크기가 같게 하여 log값을 1로 만들어 loss를 0에 가깝게 하는 것이다.
- dot product를 통하여 내적을 했을 때, 유사할수록(positive sample) 큰 값을 나오고 유사하지 않을수록(negative sample) 0에 가까운 값을 나오게 하여 모델이 feature space에서의 유사도를 활용할 수 있도록 모델을 학습시킨다.
한계점
- 모델 학습을 잘 하게 하기 위하여 Negative sample을 많이 확보할 필요성이 있는데 SimCLR에서 negative sample을 많게 하기 위해서는 큰 크기의 batch size가 필수적이다. 따라서 큰 Batch size를 올릴 수 있는 GPU memory 공간이 확보되야한다.
- 이와 같은 증명을 하기 위하여 batch size 또는 Negative sample의 수에 따른 성능 비교 논문이 있는데, 나중에 자세히 다룰 예정
- 추후 Unsupervised Contrastive learning에 대한 가장 고질적인 문제인 Positive sample의 수에 대해서 문제를 해결하기 위하여 Supervised Contrastive learning과 같은 방법론이 등장함. 하지만 결국 Supervised Contrastive learning은 contrastive learning 학습 과정에 있어서 label information이 필요하기 때문에 선택적인 부분이라고 판단됨.
'Papers > Contrastive Learning' 카테고리의 다른 글
| Contrastive Learning based Hybrid Networks for Long-Tailed Image Classification (0) | 2021.12.21 |
|---|